简介:scrapy是一个用于爬取网页并提取数据的应用框架,也可用于提取API数据
写在前面:只想看scrapy的童鞋子请跳过5-7直接step8)
step5,6是xpath和css入门,用于提取数据;
step7是文件储存方式,用于后续pinpeline配置;
step1:创建虚拟环境
打开终端:
win+r>>cmd>>pip install virtualenv(安装虚拟环境创造工具)
virtualenv ENV #创建第一个虚拟环境
cd ENV#在当前目录下创建一个ENV文件夹并进入
activate #激活,然后在终端的盘符前(ENV)则代表进入虚拟环境状态
deactivate#退出
step2:安装依赖包
创建一个.自命名txt文件,#后面不用录入,这里仅为解释
lxml#解析xml和HTML 的工具 parsel#HTML/XML数据提取 w3lib#网页解码 twisted异步网络编程框架 cryptography#用于加密 pyOpenSSL#进行加密解密操作然后终端cmd
pip install -r 自命名.txt
step3:安装scrapy
win+r>>cmd>>pip install Scrapy

step4:scrapy shell(调试代码)
定义: scrapy终端,是一个交互终端,该终端是用来测试Xpath或css表达式,查看他们的工作方式及从爬取的网页中提取的数据。
4.1、安装ipython(有高亮和补全功能)
pip install ipython
4.2、简单测试下scrapy shell
1)调试http://www.baidu.com
scrapy shell www.baidu.com
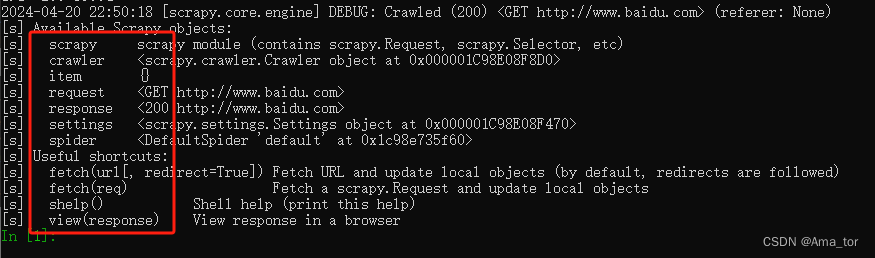
2) 测试获取标题的选择器是否正确
response.css("title").extract_first()
![]()
step5:xpath运用(xhelper用来测试xpath语句)
5.1、安装chrome插件:xhelper
官方下载:右上角三点>>扩展程序>>chrome商店>>xhelper
便捷通道:
wc:Ama爬虫
input:chrome插件:xhelper
5.2、xhelper运用:
A、解压压缩包,并加载(所以要记住下载路径鸭)

B、调用ctrl+shift+x(快捷键)或者钉一下扩展程序,这样点击就可以使用啦
在上方出现黑色框即成功调用


5.3:Xpath解析文件
5.3.1解析本地文件
# Xpath解析有两种解析文件
# 1.本地文件 etree.parse( 'xx.html')
# 2.服务器相应数据 response.read().decode('utf-8')
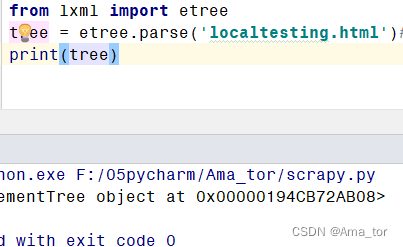
A:代码应用(解析本地文件localtesing.html):
from lxml import etree
tree = etree.parse('localtesting.html')#解析本地文件
print(tree)运行结果:
B:附-localtesting代码
#localtesting.text→localtesing.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>#meta元信息不显示在页面,是定义用途
<title>Title</title>#页面标题
</head>
<body>#正文
<ul>#无序列表
<li id='l1' class="c1">beijing</li>#无序列表项
<li id='l2' class="c2">shanghai</li>
<li id='s1'>guangzhou</li>
<li id='s2'>shenzhen</li>
</ul>
</body>
</html>
C:本地文件基于xpath的相关查询应用
xpath元素定位用法://*[@id="kw"] #基于id来查找元素
//input[@name="wd"]#基于name来查找元素
//*[@class="" and @href="http://.com/"]
#查找所有class=''和href=''的元素//*[text()="按图片搜索"]#查找文本内容为‘按图片搜索’的元素
//*[contains(@name,'r')]#查找元素中name属性值包含‘r’的元素
//*[contains(text(),'搜索')]#查询任意元素中文本内容包含‘搜索’的元素
/表示子级元素
/…表示父级元素若要定位多个元素也可用[*]
//*[@id="kw"]/..#查找任意元素中id为’kw’元素的父级元素
//*[@http-equiv]#查找任意有http-equiv属性的元素
from lxml import etree
tree = etree.parse('localtesting.html')#解析本地文件
print(tree)
r1= tree.xpath('//body/ul/li/text()')#路径查找body下ul下li
r2= tree.xpath('//ul/li[@id]/text()')#查找所有含id属性li的标签
r3= tree.xpath('//ul/li[@id="l1"]/text()')#查找所有含id为l1的li的标签
r4 = tree.xpath('//ul/li/@class')# 查<li>标签的class属性的属性值
r5= tree.xpath('//ul/li[@id="l1"]/@class')# 查找id为l1的<li>标签的class属性的属性值
r6= tree.xpath('//ul/li[contains(@id,"l")]/text()')#查找 <li> 标签的id中包含 ‘l’ 的标签
print('\n',r1,'\n',r2,'\n',r3,'\n',r4,'\n',r5,'\n',r6)运行结果如下:

5.3.2服务器文件解析(含XPATH插件调试)
from lxml import etree
import urllib.request
# 2.服务器相应数据 response.read().decode('utf-8') 【主要用这个】 etree.HTML(response.read( ).decode("utf-8")
# 1.获取网页的源码
url = 'https://www.baidu.com/'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"}
# 请求对象定制
request = urllib.request.Request(url, headers=headers)
# 模拟客户端向服务器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
# 解析服务器响应的文件
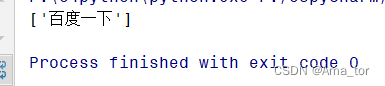
tree = etree.HTML(content)
result = tree.xpath('//*[@id="su"]/@value')
print(result) (在运行代码前对xpath的调试可以用下载拓展插件,如果很熟的同学可以忽略)
运行结果如下:
step6:CSS选择器的基本语法
import parsel#内部集成xpath,css和re语法
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
selector = parsel.Selector(response.text)
selector.css('*')#选择所有元素
html = selector.css('article')#1、选择article元素,get(), getall() , extract_first(), extract() 都可以
selector.css('#container')#2、选择id为container的元素
selector.css('.container')#3、选择所有class包含container的元素
selector.css('div a')#4、选取所有div下所有a元素
title1 = selector.css('title').extract()
title2 = selector.css('title').extract_first()#5、提取标签title列表
text = selector.css('p::text').extract()#6、提取标签p里的文本内容
data = selector.css('div.post-content *::text').extract()#7、提取标签div里的所有文本内容
url = selector.css('div.post-content img::attr(src)').extract()8、提取标签里的URL:标签名::attr(属性名)
a = selector.css('a[title]').getall()#9、选取所有拥有title属性的a元素
step7:文件储存(file VS urlretrieve)【后续与pipeline有关】
7.1file储存
写在前面:这里我们回顾一下基础python时下载图片文件用的方法:

语法总结:
file=open('自命名.文件类型','w',encoding='utf-8')#‘w’为覆盖,‘a’为追加file.write()#将数据写入文件file.close()
7.2urlretrieve储存
A:正则清洗→存储
import re#载入re库,正则应用
import urllib.request#载入urllib.request库
def getHtml(url):#定义网页请求
page=urllib.request.urlopen(url)#打开网址,赋值给page
html=page.read().decode('utf-8')#读取网站源码,定义编码形式,并赋值给html
return html#返回html参数
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'#定义正则表达式规则
imgre = re.compile(reg)#re.compile() 可以把正则表达式编译成一个正则表达式对象
imglist = re.findall(imgre, html)#re.findall() 方法读取html 中包含 imgre(正则表达式)的数据
x = 0#给x赋值0
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'A%s.jpg' % x)#urlretrieve下载imgurl(遍历imglist),并储存在相对路径下
x += 1 #每次循环x+1
html = getHtml("http://tieba.baidu.com/p/2460150866")调用gethtml函数,请求该网站,赋值给html
getImg(html)#调用getImg()函数,并写入html参数运行结果:

B:xpath提取→存储
把方法A的def getImg(html)改成xpath方式即可
import re
import urllib.request
from lxml import etree
def getHtml(url):
page=urllib.request.urlopen(url)#打开URL并发出request请求
html=page.read().decode('utf-8')#读取网址页面
return html#返回网络源码
def download(html):
tree = etree.HTML(html)#解析网络源码
src_list = tree.xpath('//div/img[@class="BDE_Image"]/@src')#获取所有图片地址
x = 0
for imgurl in src_list:
urllib.request.urlretrieve(imgurl, 'xpath%s.jpg' % x) # urlretrieve下载imgurl(遍历imglist),并储存在相对路径下,
x += 1
html = getHtml("http://tieba.baidu.com/p/2460150866")
download(html)运行结果:
step8:scrapy全局命令(终端进行)
1)建项目(startproject)
打开终端:
scrapy startproject Ama_torproject
运行结果:
2)创建文件(genspider)
scrapy genspider amaspider taobao.com
genspider为蜘蛛模板

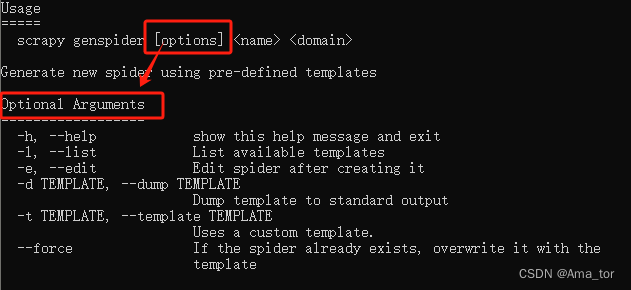
3)genspider -h查看帮助
scrapy genspider-h
4)可用模板genspider -l,查看
scrapy genspider -l

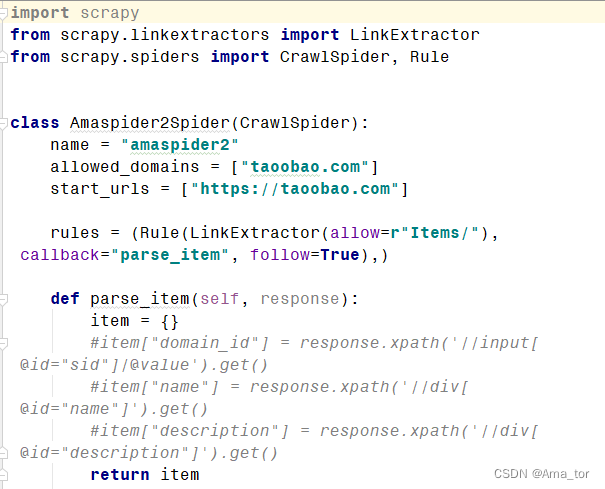
5)创建crawl型蜘蛛模板(genspider -t crawl)
scrapy genspider -t crawl amaspider2 taoobao.com
运行结果:
6)setting 查看参数
scrapy settings--get DOWNLOAD_DELAY
scrapy settings--get BOT_NAME
7)runspider基于文件运行
(scrapy crawl XX:基于项目运行)
scrapy runspider ama_texting.py
8) fetch调试:模拟蜘蛛下载页面
scrapy fetch http://www.scrapyd.cn
#>指向想要下载的地址并命名
scrapy fetch http://www.scrapyd.cn >f:/amaspider_fetch.html
![]()
9)view功能(与fetch一样)
scrapy view http://www.scrapyd.cn
step9: scrapy项目命令(指向项目文件进行)
crawl:运行name=ama的蜘蛛
scrapy crawl ama
list:得到蜘蛛名字
scrapylist
check、edit、parse、bench
step10:示例应用(摘录quotes网站的名人名言)
终端操作$:
$Scrapy startproject Ama_spiderman
$cd Ama_spiderman
$scrapy genspider famousquotes quotes.toscrape.com
四大基础步骤:代码编写与配置
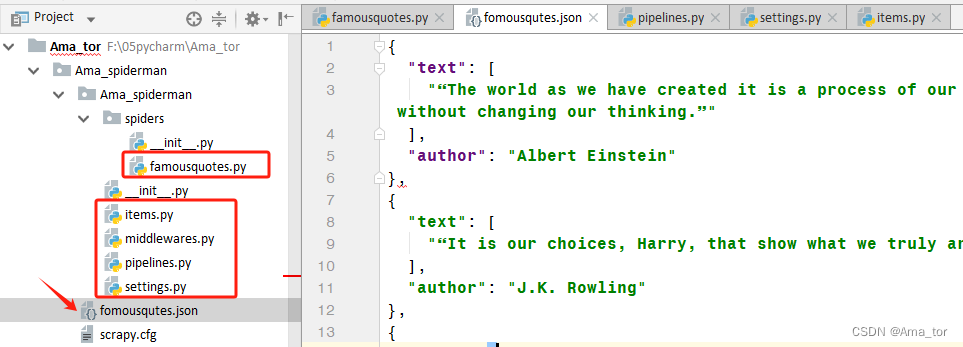
5、最终的运行结果为:fomousqutes.json文件
1、famousquotes.py 2、pipelines.py 3、settings.py 4、items.py
源代码展示:
1、直接在scrapy生成的famousquotes.py里面改def的内容
import scrapy from ..items import AmaSpidermanItem class FamousquotesSpider(scrapy.Spider): name = "famousquotes" allowed_domains = ["quotes.toscrape.com"] start_urls = ["https://quotes.toscrape.com"] def parse(self, response): item=AmaSpidermanItem() for quote in response.css('div.quote'):#查找所有class为quote的div标签 item['text']=quote.css('span.text::text').extract_first(), item['author']=quote.xpath('span/small/text()').extract_first() yield item#通过生成器yield将字典内容传给pipeline中进行下一步处理 next_page=response.css('li.next a::attr("href")').extract_first() if next_page is not None: yield response.follow(next_page,self.parse)2、这里用到前面step7大类讲到的file储存语句,也是直接到生成的文件里改内容。
import json class AmaSpidermanPipeline: def __init__(self): self.file=open('fomousqutes.json','w',encoding='utf-8') def process_item(self, item, spider): item=dict(item)#将item对象转为字典,仅在scrapy中使用 json_data=json.dumps(item,ensure_ascii=False,indent=2)+',\n'#将字典数据序列化 self.file.write(json_data)#将数据写入文件 return item def __del__(self): self.file.close()3、pipelines解锁两part:
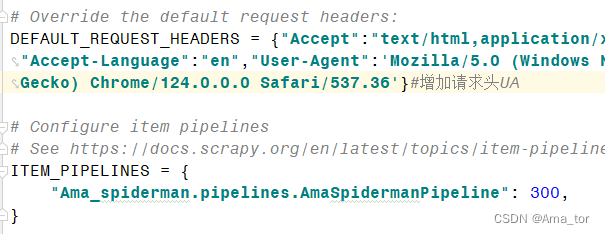
DEFAULT_REQUEST_HEADERS,去掉#解锁后加上自己的header-UA即可; ITEM_PIPELINES,直接解锁(自动生成)
4、items.py
import scrapy class AmaSpidermanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() text=scrapy.Field() author=scrapy.Field()
项目操作$:
$scrapy crawl famousquotes
运行结果:
参考来源如下:
- 《python3爬虫实战》-作者:姚良-出版社:<中国铁道出版社有限公司>
- 《爬虫解析——Xpath的安装及使用(五)》作者:Billie使劲学http://t.csdnimg.cn/5EeX8)
- 《python实现简单爬虫功能》-作者:虫师,https://www.cnblogs.com/fnng/p/3576154.html
- 《scrapy爬虫Spiders的用法》水墨黑https://www.cnblogs.com/shuimohei/p/13340258.html
- 《Scrapy 爬虫框架[通俗易懂]》全栈君Scrapy 爬虫框架[通俗易懂]-腾讯云开发者社区-腾讯云
- 《python爬虫parsel-css选择器的具体用法》-作者:程序员王炸-http://t.csdnimg.cn/I0NgF
- 《Python爬虫必备—>Scrapy框架快速入门篇——上》作者:孤寒者http://t.csdnimg.cn/UecLt